
GRIP: Generating Interaction Poses Using Spatial Cues and Latent Consistency
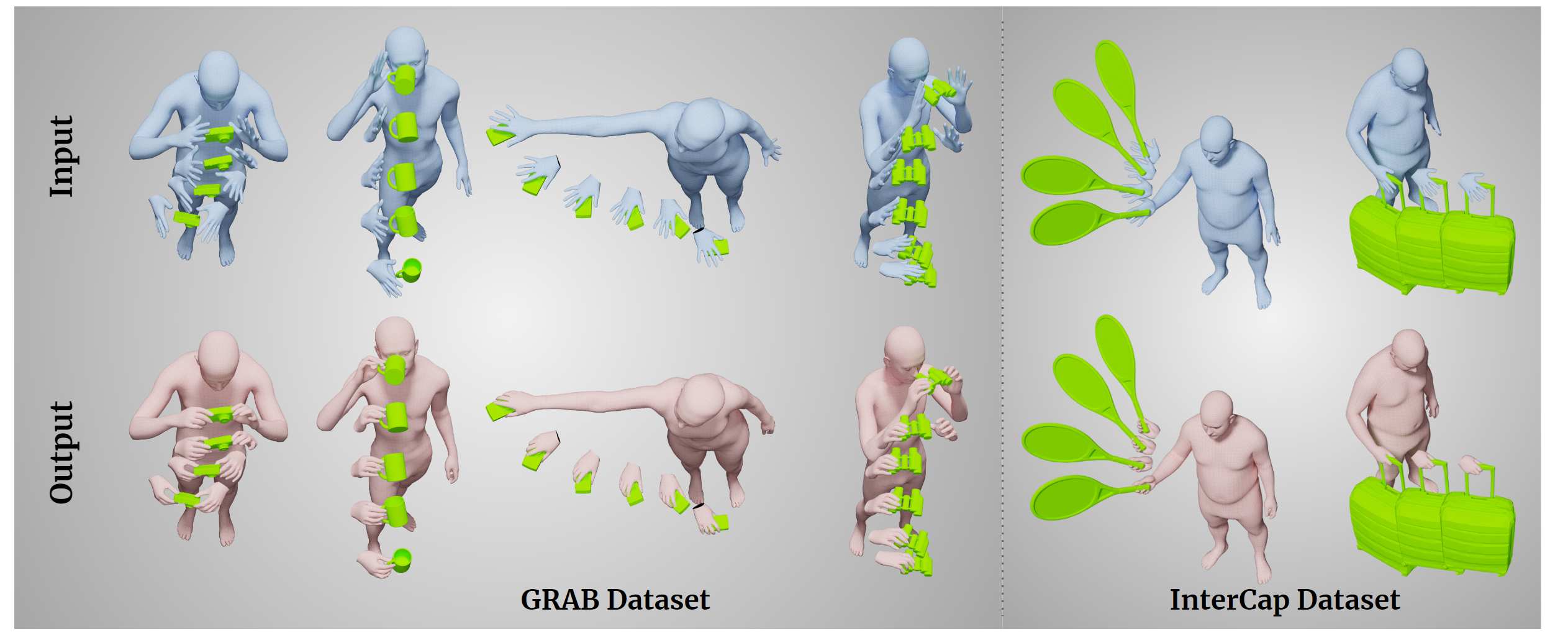
Results
Abstract
Video
Data and Code
Please register and accept the License Agreement on this website to access the GRIP models.
When creating an account, please opt-in for email communication, so that we can reach out to you via email to announce potential significant updates.
- Model files/weights (works only after sign-in)
- Code (GitHub)
Referencing GRIP
@inproceedings{taheri2024grip,
title = {{GRIP}: Generating Interaction Poses Using Latent Consistency and Spatial Cues},
author = {Omid Taheri and Yi Zhou and Dimitrios Tzionas and Yang Zhou and Duygu Ceylan and Soren Pirk and Michael J. Black},
booktitle = {International Conference on 3D Vision ({3DV})},
year = {2024},
url = {https://grip.is.tue.mpg.de}
}
Disclaimer
MJB has received research gift funds from Adobe, Intel, Nvidia, Meta/Facebook, and Amazon. MJB has financial interests in Amazon, Datagen Technologies, and Meshcapade GmbH. While MJB is a consultant for Meshcapade, his research in this project was performed solely at, and funded solely by, the Max Planck Society.
Acknowledgments
This work was partially supported by Adobe Research (During the first author's internship), the International Max Planck Research School for Intelligent Systems (IMPRS-IS), and the German Federal Ministry of Education and Research (BMBF): Tübingen AI Center, FKZ: 01IS18039B.
We thank:
- Tsvetelina Alexiadis and Alpár Cseke for the Mechanical Turk experiments.
- Benjamin Pellkofer for website design, IT, and web support.